Many organizations need to generate forecasts at very detailed levels. For example, a consumer products company may need an SKU-by-customer forecast, a shoe manufacturer may need a shoe-by-size forecast, or an automobile manufacturer may need a parts-level forecast. One approach to generating low-level forecasts is to apply statistical forecasting methods directly to the lowest-level demand histories. An alternative approach is to use statistical forecasting methods on more aggregated data and then to apply an allocation scheme to generate the lower-level forecasts.
Many organizations need to generate forecasts at very detailed levels. For example, a consumer products company may need an SKU-by-customer forecast, a shoe manufacturer may need a shoe-by-size forecast, or an automobile manufacturer may need a parts-level forecast. One approach to generating low-level forecasts is to apply statistical forecasting methods directly to the lowest-level demand histories. An alternative approach is to use statistical forecasting methods on more aggregated data and then to apply an allocation scheme to generate the lower-level forecasts.
Deciding upon the lowest level at which to generate statistical forecasts and deciding how to allocate a statistical forecast to lower levels can have a major impact on forecast accuracy. This installment of Forecasting 101 examines some of the issues surrounding these decisions including how the “forecastibility” of data changes at different levels of aggregation.
Can it be Simpler?
Prior to deciding what levels of your forecasting hierarchy should be forecasted using statistical models, it is useful to consider whether your forecasting hierarchy can be simplified. Just because you have access to very detailed information, does not mean it should be forecasted. If a forecasting level is not strictly required—it should not be included in your forecasting hierarchy. Your goal is to always keep your forecasting hierarchy as simple as possible, while still getting the job done.
If your management asks whether you can generate a forecast at a lower level than you are currently forecasting, you may need to educate them about why this may not be the best choice. You will need to explain that the forecasts are likely to be less accurate than your current forecasts, that forecasting at a lower level will complicate the forecasting process considerably and question whether such forecasts are truly needed by the organization. As Einstein put it, “Everything should be made as simple as possible, but not simpler.”
Do You Have Enough Structure?
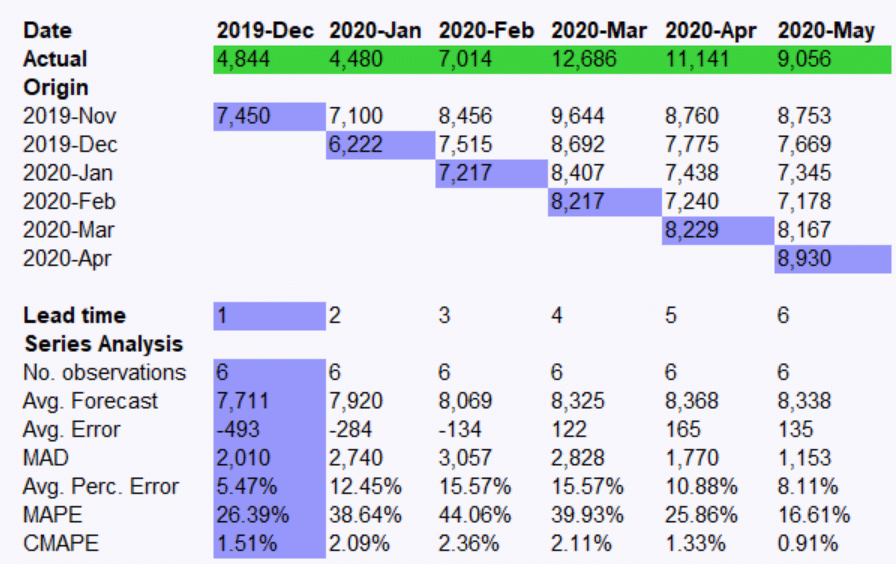
Figure 1 shows monthly sales for a brand of cough syrup. Figure 2 shows monthly sales for a specific SKU. The company assigns a unique SKU number to each flavor-by-bottle size combination that it produces.
Figure 1: Brand level

Figure 2: SKU level

Consider the two graphs. Notice that at the brand level, there is more structure to the data. The seasonal pattern is readily apparent and there is less “noise” (random variation). More than three years of demand history is available at the brand level, while only 10 months of history exists for the recently introduced SKU. In general, when you disaggregate data, the result is lower volume, less structure and a data set that is harder to forecast using statistical methods.
Many organizations that need to generate low-level forecasts discover that at the lowest levels there is not enough structure to generate meaningful statistical forecasts directly from the low-level data. In these cases there is little choice but to generate the lowest-level forecasts not with statistical models, but rather by using some type of top-down allocation scheme.
Are the Relationships Between Levels Changing in Time?
A statistical model uses past demand history to forecast how things are changing in time. If there is a relationship between two levels of your hierarchy that is time independent, then you may be able to define an allocation scheme to forecast the lower level rather than trying to forecast it based on history.
For example, a shoe manufacturer needs a forecast for a men’s running shoe for each size manufactured. The demand for the specific style of shoe is changing in time, so the shoe-level forecast should be generated using a statistical method to capture the change. On the other hand, the size of runners’ feet is not changing rapidly in time, so the by-size forecasts can be generated by allocating the shoe-level forecast to the sizes using a size distribution chart.
Another example might be an automobile manufacturer who uses a statistical model to forecast vehicle sales and then allocates via a bill of materials to generate a parts-level forecast.
In both of these examples, because the relationship between the levels is known and not changing in time, the allocation approach will likely be more accurate than trying to statistically model the lower-level data.
Summary
Deciding how to organize your forecasting hierarchy and how to forecast each level can have deep ramifications on forecast accuracy. As you make these important decisions, you need to: (1) question whether you have simplified your hierarchy as much as possible; (2) determine what levels have enough structure for you to apply statistical methods directly to the data and (3) understand the relationships between the levels—particularly those where a logical allocation scheme could be used to generate the lower-level forecasts.
About the author:
 Eric Stellwagen is the co-founder of Business Forecast Systems, Inc. and the co-author of the Forecast Pro software product line. He has consulted widely in the area of practical business forecasting and regularly presents workshops on the subject. He has worked with many leading firms including Coca-Cola, Procter & Gamble, Merck, Blue Cross Blue Shield, Nabisco, Owens-Corning and Verizon. He has presented seminars and workshops under the aegis’s of many groups including the Institute for Professional Education, the American Production and Inventory Control Society, the University of Wisconsin, the Institute for Business Forecasting, the World Research Group, the International Institute of Research, the Electric Power Research Institute, the International Communications Forecasting Association and the International Institute of Forecasters. He is currently serving on the board of directors of the International Institute of Forecasters and on the practitioner advisory board of Foresight: The International Journal of Applied Forecasting.
Eric Stellwagen is the co-founder of Business Forecast Systems, Inc. and the co-author of the Forecast Pro software product line. He has consulted widely in the area of practical business forecasting and regularly presents workshops on the subject. He has worked with many leading firms including Coca-Cola, Procter & Gamble, Merck, Blue Cross Blue Shield, Nabisco, Owens-Corning and Verizon. He has presented seminars and workshops under the aegis’s of many groups including the Institute for Professional Education, the American Production and Inventory Control Society, the University of Wisconsin, the Institute for Business Forecasting, the World Research Group, the International Institute of Research, the Electric Power Research Institute, the International Communications Forecasting Association and the International Institute of Forecasters. He is currently serving on the board of directors of the International Institute of Forecasters and on the practitioner advisory board of Foresight: The International Journal of Applied Forecasting.